2 min audio
Most people treat computer vision monitoring as just “tracking accuracy.”
I used to think the same—until I deployed models into the messy, unpredictable real world.
What I learned is simple:
Models don’t just fail. They drift conceptually. And because they drift in specific ways (lighting changes, camera bumps, weather), they create signals that are easy to miss if you only look at top-line metrics.
This post is a recap of why I built VIRK (Vision Incident Response Kit)—a flight recorder for CV pipelines—and the patterns that matter most in production.
The 3 biggest failure patterns I noticed
1) Accuracy is a lagging indicator (and often impossible to get)
In production, you rarely have immediate ground truth labels. Waiting for human review means you are reacting days or weeks late.
Instead of waiting for labels, I saw that monitoring embedding drift gave me a realtime pulse.
- High drift magnitude often preceded accuracy drops.
- Sudden spikes indicated environmental shocks (e.g., lights going out).
This is exactly why Drift Detection > Accuracy Monitoring for immediate operational health.
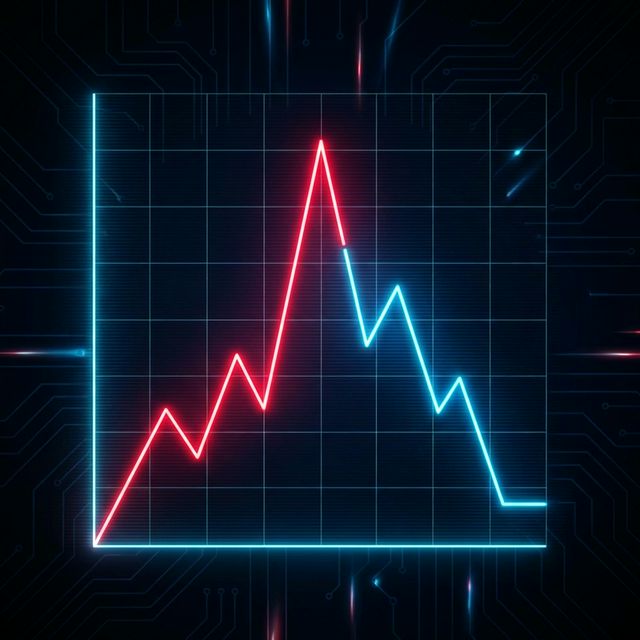 Figure: Drift spikes (red) often predict performance degradation long before labels arrive.
Figure: Drift spikes (red) often predict performance degradation long before labels arrive.
2) “Something is wrong” isn’t actionable
Telling an engineer “the model is drifting” is useless. They need to know why.
I found that generic drift scores were just noise without context. The real signal comes from fingerprinting the cause:
- Is it a brightness shift? (Camera exposure issue)
- Is it motion blur? (Camera mounting loose)
- Is it new semantic classes? (New product type)
So I built a Fingerprinter that diagnoses the root cause automatically.
3) Reproducibility is the nightmare
This is the most practical lesson from on-call rotations:
If you can’t reproduce it, you can’t fix it.
For at least some incidents, the “bad data” was transient. By the time we looked, the stream was back to normal.
That implies:
- You capture the exact batch of images that caused the drift.
- You capture the metadata and model state.
- You create an executable replay script.
I automated this with the Incident Bundler, which zips up everything needed to replay the failure locally with one command.
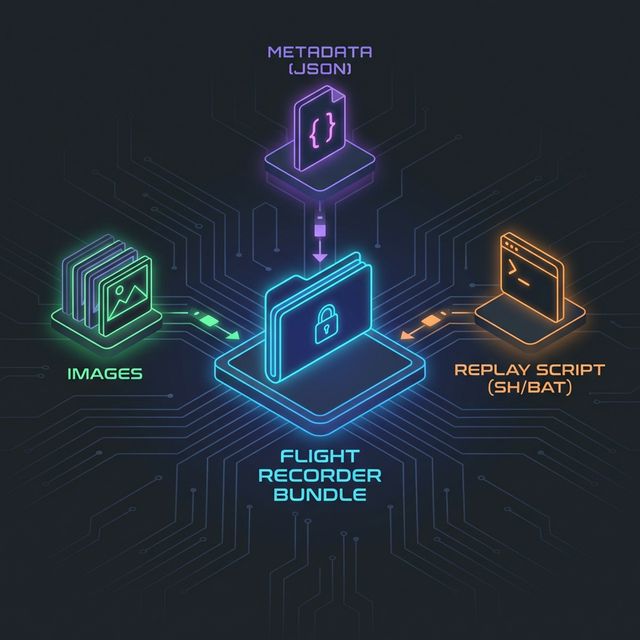 Figure: An incident bundle contains everything needed for local reproduction: images, manifest, and replay script.
Figure: An incident bundle contains everything needed for local reproduction: images, manifest, and replay script.
The “Flight Recorder” Mindset
Once you accept that failures are inevitable, the goal shifts from “prevention” to “fastest possible diagnosis.”
High-assurance vision systems need a black box.
So I designed VIRK to sit alongside the inference service:
- Async & Non-blocking: It never slows down the main prediction loop.
- Load Shedding: If the system is overwhelmed, it drops diagnostics, not predictions.
- Privacy-aware: It only saves data when an incident is detected.
Why this matters
If you monitor blindly, production vision systems feel fragile and opaque.
If you monitor drift + root cause + reproducibility, incidents become manageable:
- You know when it’s happening (Drift).
- You know why it’s happening (Fingerprint).
- You have the data to fix it (Bundler).
That’s the reliability standard we need for modern MLOps.
Project link (if you’re curious)
I built this toolkit for myself and open-sourced it:
GitHub: Vision Incident Response Kit (VIRK) Documentation: Read the docs
Setup is a single pip install away. Let me know what you think!